|
|
Quick Scroll To:
Introduction
Generating and representing environmental databases is a key factor in networked simulation systems. It's particularly demanding to create an environment that looks good when traversed at ground level, instead of at 30,000 feet in a flight simulator. Real-time networked simulation places additional constraints on the successful creation of these environments. Because the use of three-dimensional environments in commercial, educational, and entertainment applications will increase, and because these applications will be connected via local and global networks, it is important to understand how environmental databases can impact networked systems. This section describes some of the challenges associated with the creation and use of these environmental databases for ground and near-ground applications in a networked simulation system.
The representation of the information for a particular terrain can be drastically different based on the needs of a simulation platform, or the specific application. We touch on these diverse computing needs and how they affect the creation and exchange of a terrain database in a networked heterogeneous system. For example, creation of electronic or paper maps demands a data representation scheme that may not be suitable for a thermal sight simulator, even though both are intended to depict and operate in the same geographical region.
This section reviews the key steps in creating databases and highlight the trade-offs in source data selection, geometric representations, and issues such as interchange and interoperability. Also discussed are some management considerations in improving the process, quality of simulation, and tool development.
Background
Military training simulation systems have been around for decades. Most of these systems have used some derivation of the real environment to represent a slice of the three-dimensional reality. These have ranged from the actual physical environment, to detailed analog models of a small region, to a completely digital version. In the last three decades the price-performance benefits of computer technology and the demand for reconfigurable, less expensive, and more realistic representations have driven simulation systems towards real-time digital computing and fully synthesized environments. As a result, capturing and depicting "a slice of the three-dimensional reality" with more precision and fidelity has become more difficult.
Until the early 1980's, simulators were mostly stand-alone systems designed for a specific task training purpose. Until the introduction of the SIMNET program, no one had ever used a multitude of simulators in a combined forces training environment, interacting over a network in real-time. SIMNET technology allowed crewmembers in one simulator, to interact in real-time in the same depicted environment with many other manned or unmanned simulators located at the same or other training sites. The interaction takes place within a digitally synthesized environment that represents some region of Earth. Each simulator maintains its own copy of this "synthetic" region.
In addition to the challenges in building environmental databases for stand-alone simulators, networking imposed new and stringent demands on the techniques and the process. The initial implementation of SIMNET created a system of homogeneous manned simulators. The idea of using heterogeneous simulators on one network creates even greater challenges in constructing, distributing, and using environmental databases. These are the key problems the real-time networked simulation community still faces today, and in spite of the rapid acceptance of this technology in the past decade, the techniques for interoperating heterogeneous simulation systems are still being researched, developed, and designed. So before discussing issues regarding environmental databases for networked simulation, we should review the more general construction and utilization issues of these environments that apply, in most cases, to both networked and stand-alone systems.
What Constitutes an Environmental Database?
In this section, the words "terrain database" and "environmental database" are used synonymously and interchangeably, although a terrain database is often a subset of a full environmental database. An environmental database is an integrated set of data elements, each describing some aspect of the same geographical region. It often includes additional data describing simulation elements and events expected to take place during the interactions in that environment. For example, data representing trees in a forested region may be found in a database; but in addition, the geometry of vehicles that might drive through the trees during a simulation would also be found in an environmental database.
The key phrase in the above definition is "integrated set of data." It is the integration, infusion, and tailoring of varied data sources that creates a full database, and sets it apart from databases that only use an existing raw data source as-is. The following sections discuss some of the more important data elements that are integrated into a simulation database.
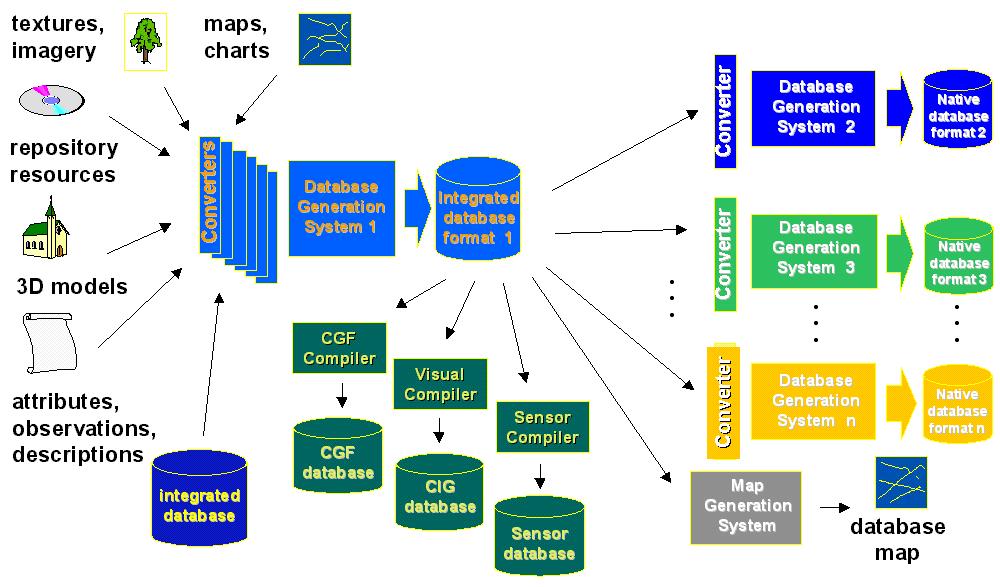
It is the combination of all these data sources, and more, that is used in the construction of a database and constitutes an integrated environmental database. Integrating this data into a coherent database creates a source database that can be shared by many players. In networked simulation it is some flavor of this "integrated" database that is viewed as the source for input into other simulators' computational systems. The figure below represents the steps in creation and distribution of an integrated database.
.
.
Applications Using Environmental Data
The range of potential players in a networked heterogeneous simulation system is both wide and varied, but predominantly they fall into the five major application categories discussed in the following sections. The needs of each application for representation of the data of the same exact geographical region can be extremely different, even though the underlying "information" is identical.
Same Object, Multiple "Views"
When different simulation applications are operating over the same geographical region, each has a different perspective and "view" of the same object in that region. Multiple representations of the same objects are usually needed to address this difference. Sometimes the data in an environmental database doesn't contain the required information, even though it may adhere to the appropriate data format. In these cases the application must obtain this information by either extracting (often reverse-engineering) the data that is in a database, or inserting it from other sources. And sometimes the information does exist, but not in the optimum format. Both of these data augmentations are most often accomplished when an application downloads the simulation source database and prepares it for its own use. This is called the database conversion process, and is typically an off-line step prior to any real-time simulation.
Even within the same class of application platforms the information and data needs may be different. Let's say the same visual system is used to render images for two different simulation purposes; a ground vehicle and an aircraft, both operating in the same geographical region. For proper operation, the ground vehicle requires detailed geometric data describing the surface of the terrain and the 3D objects on the terrain. Surface slopes, location and size of obstacles, and other important details must be specified with sufficient fidelity so the vehicle operator can maneuver through the environment. The same surface slope, on the other hand, is of no consequence to the pilot of the aircraft simulator flying at thirty thousand feet over the same region. In that case a reasonable 2D image of the area is all that's required to indicate where the ground is.
In one case 3D polygons are needed; in the other an image representing the same area will suffice. Both applications use the same type of image generator, but allocate the computational load differently. The aircraft requires longer viewing ranges at high altitudes, but doesn't need high detail geometry. The ground vehicle has a more restricted viewing volume, but needs more detail in nearby objects.
This difference in representations of the same objects and regions can have a significant impact on an environment database. Such diversity in data representation is largely independent of whether the simulators are networked or not.
The data representation problem becomes more complicated when the same database must be used not only with different fidelity systems, but also with different types of systems. For example, a CIG, SAF, and a map generator require different information to process a road network. The CIG must render the road geometry using 3D surface representation, then add color and texture data so a driver can recognize and follow the road. Additional data for transition regions between the road and the surrounding terrain, or about surface composition used for vehicle dynamics, may also be necessary.
A SAF system, on the other hand, not only requires the 3D surface geometry to properly place its vehicles on the road, but also needs topological data so the vehicles can actually follow the turns and bends of the road. Since there is no human eye to guide a SAF vehicle and avoid obstacles, the system must have sufficient data to "drive" a vehicle reasonably intelligently. This topological data must exist in the SAF version of the database, but is unnecessary for the CIG system's database. Similarly, the SAF system will have no use for the texture and color portion of the surface data.
The map generator can utilize the same topology data a SAF system needs, but has to process these as 2D line drawings at the appropriate scale. Texture data and 3D geometry are of little significance to the map generator, but it needs road names, road types (freeway or dirt road), and labels to produce a paper or electronic map.
In these examples, all three systems need access to the same conceptual object (the road and the surrounding terrain), but the types of information and the data format needed by each is different. To interoperate these different fidelity systems, a complete environmental database must accommodate all their needs. Otherwise the maps may not represent what a driver sees in his viewports, or the SAF vehicles may appear to be driving off the road when viewed from a manned simulator. Each representation of the data must be taken into account in the creation and use of environmental databases.
Although in these examples we have focused on terrain databases, similar challenges and issues exist for systems that require atmospheric, oceanographic, maritime, or space environmental data.
Constraints on Making Databases
There are several constraints on the creation of environmental databases. Perhaps the most prominent of these is dictated by the real-time computation requirements. Since processing power is limited, once a computing platform is chosen for a given cost-performance range, the software, and sometimes the hardware, must be designed for best real-time performance. This means both the data and the data structures stored in a platform-specific version of an environmental database play an important role in optimizing the system performance. These optimization concepts are no different than what the computer game industry does in authoring every game; it's simply a matter of scale, at least in non-networked systems. Given the fixed computational budget of a system, the database designer must take into account the application-specific requirements, the size and extents of the database, the desired density and fidelity, as well as the type and amount of the available raw data elements that must be incorporated into the database.
If a networked simulation system is the target, then whether it is composed of a homogeneous or heterogeneous set of simulators makes a big difference in the design and distribution mechanism of the database. As the previous examples show, multiple representations of the same object require the designer to take these needs into account during the construction process. In many cases the needs of all potential participants are not accommodated during the database construction phase. For example, in most of today's terrain databases topology data is either non-existent or lost during the database creation, and the database user who needs this information must attempt to extract this information from the database that has been received.
Other application-specific requirements relate to whether the database will be used for air, ground, sea, near ground, or any combination of these simulators. The detail needed by a simulator that allows an individual to walk on the terrain is much greater than that expected for a helicopter simulator typically flying several hundred feet in the air. Database density, size and extents, viewing range, field of view, and other important simulation requirements dictate the amount and type of data that can be included in a database without overwhelming the performance requirements.
Often the intended simulation platform imposes specific constraints. This is most notable in the computer image generator (CIG) systems. The specific special purpose hardware architectures, designed for the sole purpose of real-time image generation, impose vastly different constraints on the database contents. Two database designers building a database of the same region for two different CIGs often arrive at entirely different end results. The polygon or object processing capacity of a CIG limits the database density to levels that can be processed in real-time. Similarly, image rendering techniques drive whether a database can contain textures and how many, or if the image generator can render all the objects that are potentially viewable in a scene within a fixed frame time. Other architecture-specific features such as caching scheme, occulting calculation, processing of transparent objects, or image enhancement techniques like anti-aliasing drive how a database must be partitioned, what additional run-time data needs to be added to speed operations, and whether certain data elements can even be included.
These types of computation constraints are not unique to visual systems. Any information technology application that must achieve specific real-time performance measures has to reflect such objectives in its design. This in turn impacts the data structures, data types, and the information that is needed and expected to be available from an environmental database.
Even if networking is not a goal, the above examples show that there are many constraints that must be taken into account by a database designer for creating an environmental database. When networking is a goal, the diversity in computation power poses severe problems for interoperability of multi-fidelity heterogeneous systems. Before discussing these in more detail, let's review a typical database creation process.
Steps in Making an Environmental Database
There are different approaches to database construction depending on the available tools, intended simulation platforms, system requirements, available data sources, design preferences, and application-specific needs. As a result, there is no standard methodology for creating simulation databases. For the most part, however, some general phases are common to all database construction processes. Sometimes these phases overlap or are combined, sometimes one is left out because there is no added benefit, and sometimes their order of execution is changed or done in parallel. With those caveats, we can break the construction process into the following six phases.
Other tailoring techniques involve the partitioning of the data into spatially organized sub-regions in order to speed up access, retrieval, or processing.
Trade-offs
Real-time processing capacity dictates the need for trade-offs. Given a fixed frame rate, the computational capacity of a simulation platform will be limited to a set number of processing primitives. For example for most manned simulators that include visual systems, this translates into a fixed number of polygons and pixels that can be processed per second. The database designer, knowing the maximum capacities, makes trade-off decisions in allocating the polygon budget to various objects. For example, representation of the terrain may get a smaller budget in order to allow higher feature density in the database. Similarly, if a specific viewing range is needed for the application, database density may have to be adjusted to permit longer viewing ranges within a constant view volume. In addition, the designer must trade-off between the number of polygons allocated to static 3D structures, other features such as roads and forests, and the average expected number of moving vehicles that may congregate within a crewmember's view volume when the simulation is running.
The storage volume of the database must also be taken into account. There are times when the real-time processing capacity has not been exceeded, but the database cannot be stored in on-line memory due to its excessive size. The number of texture patterns that can be stored with a database is a good example of this situation. Also, it's possible that the database itself is populated with many simple features, and even though the object/polygon processing capacity of the machine is not exceeded, the on-line memory cannot hold the description of all the individual objects placed in the database. Partitioning and organizing the database so data can be cached efficiently at runtime often becomes another constraint that the database designer has to take into account. The construction of a database is often a balancing act between the various competing data objects and constraints.
Similar to CIGs, other simulation platforms must adhere to their processing capacity limitations. These include such things as data retrieval rates, collision detection calculations, ballistics calculations, and the time it takes to compute a vehicle's behavior given the surface geometry of a dense database. In any of these cases, if the environmental database causes excessive demands on the system's processing capacity, the database must be re-engineered to bring the real-time computation within manageable limits.
Effects of Networking
Additional issues must be considered when systems are networked to operate in a common, fully interactive, environment. This interactive free-play nature of a networked simulation can lead to unpredictable computational loads. This will be increasingly true in future entertainment, education, and various other information technology applications as the number of multi-player networked systems increases. Since players can choose to congregate in large numbers, the equivalent database density in these regions during run-time can exceed the processing power of at least some of the simulators. Although some scenarios may be predictable, there is no guarantee a system won't experience overload. To a great extent, this can be helped with proper design of the database. The designer takes into account an expected average load due to the processing of moving vehicles. This expected average is based on the anticipated scenarios, the number of objects/vehicles that are expected to participate in an exercise, and the typical processing required for handling a single object/vehicle. This average reserve is then subtracted from the total system capacity, and the database is designed based on the remaining budget.
During overload conditions some simulators employ graceful degradation techniques for managing overload. Although this is a run-time technique, the database designer can facilitate its implementation by incorporating multiple levels of detail (LOD) of an object into the database. LOD is used to reduce computational burden in normal, as well as overload, conditions. When an object is sufficiently far away, a lower level of detail is used instead of the full-fidelity original. Since details at large distances are not viewable by a user, the designer can avoid unnecessary computation of the full detail object. A database designer may assign and generate multiple LODs per object. Then, during overload conditions, the system-processing load can be reduced by switching to lower LODs of objects in the scene. Some systems extend this technique to terrain geometry as well. In networked simulation this may cause other problems, depending on the viewing range configuration of the systems involved.
Other critical factors in a database that could affect interoperability of networked systems are color, texture, haze, and contrast resolutions and settings. These can vary from system to system, and can create unfair advantages for some users. They often lead to differences in speed of detection and recognition of distant objects.
Interoperability and Interchange
Interoperation of multi-fidelity systems on the same network is highly desirable, in fact it is often demanded. The primary reason is to leverage existing hardware investments in legacy stand-alone simulators. The challenge, however, is in determining the "right" type and amount of environmental data that each simulator should use to ensure interoperability. The rules for interoperability of heterogeneous simulators remain unknown for the most part. Some of this is because there are very few multi-fidelity networked systems in operation today, and enough research and experimentation has not been done to arrive at general rules. Most successful heterogeneous networked exercises to date have been conducted under restricted conditions.
A common misconception is to equate success in the interchange of data with success in interoperability. Interchange of data does not guarantee interoperability, but is one necessary condition for achieving it. Since the variables affecting interoperability are many and complex, effective mechanisms for making the database interchange process successful become significantly more difficult and challenging. Examples in previous sections showed the need for multiple representations of the same object, the trade-offs made during the construction and run-time stages, and the processing capacity of different systems. All of these are significant contributors to the type and amount of data each system can use and handle. These demands must be met successfully by the contents of an environmental database, and that is not a trivial problem.
SEDRIS was initiated in 1994 to begin addressing the interchange problem. The goal of SEDRIS is to provide the means for capturing all the pertinent information that is needed for the representation of all types of environmental databases (not just terrain). Another SEDRIS objective is to allow multiple access paths for getting to the same information, while providing polymorphic representation of the same object. The networked simulation community needs a robust environmental database interchange mechanism so it can begin addressing the interoperability issues of heterogeneous simulators.
Tools
A critical factor in constructing and sharing environmental data is incorporation and use of good tools. Most existing tools are understandably special purpose, given the various criteria and techniques employed by different suppliers for constructing and tailoring databases. As the domain of networked simulation expands and commercial applications of this technology in education, entertainment, and other information technology sectors emerge, the need for more common and yet more sophisticated tools will increase. The interest and rapid growth in use of web sites, the diversity of their content, and the desire to provide 3D interfaces are prime indicators that rich content, robust and extensible interchange mechanisms, and tools to support and create such environments are needed. The ability to create databases rapidly, to evaluate trade-off consequences and alternatives, to regenerate "missing" data, and to optimize and inject platform-specific constraints into the database will lead to the need for better database and content generation tools. Efficient tool kits are also needed during the interchange of databases. Intelligent access mechanisms and transparent data retrieval methods are critical for a good interchange process.
For the next few years and in the multi-user networked-based application domains (such as Internet), tools for interchange and tools for content development will most likely grow in parallel, and to some extent on common but competing grounds. Interchange formats will try to drive the application content, and application developers will push the interchange envelope. Once the functional and technical differences between runtime and off-line developments take better shape, the relationships between these tools will become more complementary. By contrast, the networked location-based entertainment (LBE) field will likely attend to the growth of content development tools more than interchange tool kits. The perceived competition for stand-alone networked systems will obviate the need for interchange tools. This trend will certainly change once the Internet-based systems begin to solve the interoperation of heterogeneous systems. The market demand for networked but isolated application sub-domains to connect to other sites, as well as home-based systems will once again push the state of the art in database development and interchange tools.
Summary
This has been an overview of the key issues in construction and use of environmental databases in real-time networked simulation. We reviewed the general steps in creating databases and highlighted some trade-off examples. An important aspect of database construction is the integration of many sources into one database. Application and performance constraints play key roles in the construction of these databases. The effect of simulator interoperability on the content structure of environmental databases is one of the largest challenges we face.
Tools will always play an important role in the construction, tailoring, and distribution process. Increasingly, those managing simulation projects will find themselves demanding better and more intelligent tools for the database generation tasks. They will also see a growing need for teaming designers and users, and for increasing the knowledge levels on both sides. In short, capturing, generating, and interchanging the "critical data and information" will become core to the proper use of environmental databases in real-time networked interactive information technology applications. The simulation community stands at the forefront of this endeavor.
|
|